
走過了資料分析、演算法選擇後,
我們得知了有些可以改善模型的方向:
今天我要來著手處理資料不平衡的問題!
資料不平衡的原因有許多,
像是罕見疾病的資料(全世界只有10人擁有的疾病),
或是隱私性高的資料(信用卡刷卡資料)。
要解決這個問題,通常有兩種選擇:
資料增強就是增加資料的變化性並且增加資料量。
我用旋轉、剪裁和縮放來創造出更多的圖片random_rotation:rg = Degree of rotationrandom_shearintensity = Transformation intensity in degreesrandom_zoom:zoom_range = Zoom range for (width, height).
def augmentation_image(img_array):
tf.random.set_seed(52671314) #設定隨機種子
img_array = random_rotation(img_array, rg=30, channel_axis=2) # 旋轉
img_array = random_shear(img_array, intensity=20, channel_axis=2) # 錯切
img_array = random_zoom(img_array, zoom_range=(0.8, 0.8), channel_axis=2) # 縮放
return img_array
samples = np.random.choice(len(X_train), 9)
fig, ax = plt.subplots(3, 3, figsize=(10, 10))
for i, image in enumerate(X_train[samples]):
plt.subplot(3, 3, i + 1)
plt.imshow(image.astype(np.float32)/255)
plt.title(
f"{int(y_train[samples][i])}: {emotions[int(y_train[samples][i])]}")
plt.axis("off")

fig, ax = plt.subplots(3, 3, figsize=(10, 10))
for i, image in enumerate(X_train[samples]):
image = augmentation_image(image)
plt.subplot(3, 3, i + 1)
plt.imshow(image.astype(np.float32)/255)
plt.title(
f"{int(y_train[samples][i])}: {emotions[int(y_train[samples][i])]}")
plt.axis("off")

其實上面做的事情只是簡單的矩陣運算!
複習矩陣運算請到均一教育平台,
上面有許多精彩的課程和點數機制讓你"學"不釋手。
另外,
我覺得這篇《圖像的仿射變換》說得很好,
小弟我就不獻醜了。
我將X_train經過資料增強,
使每一個類別的數量都一樣多(7類照片,每類7215張照片)。
擴大後的資料集稱作X_train_all。
我用X_train_all訓練模型,一樣用X_val來驗證模型。
訓練出來的模型就叫做EFN_aug。
拿來和EFN_base(baseline)做比較:
模型 | 訓練時長(秒) | acc | loss | val_acc | val_loss
------------- | ------------- | ------------- | -------------
EFN_aug | 4094 | 0.955 | 0.129 | 0.617 | 1.904
EFN_base | 2004 | 0.952 | 0.139 | 0.617 | 1.905
EFN_aug大概比EFN_base多花一倍的訓練時間,
這是合理的,畢竟資料量也是兩倍差不多。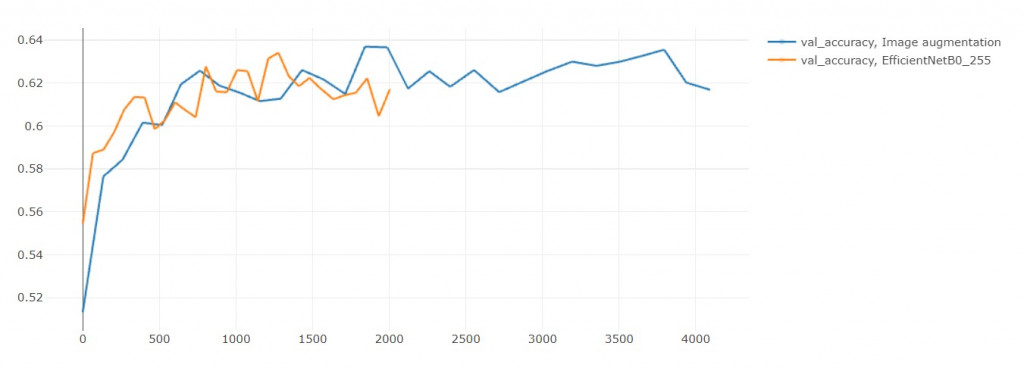
結果準確率沒有提升
(但其實在第29輪是超越原本模型的)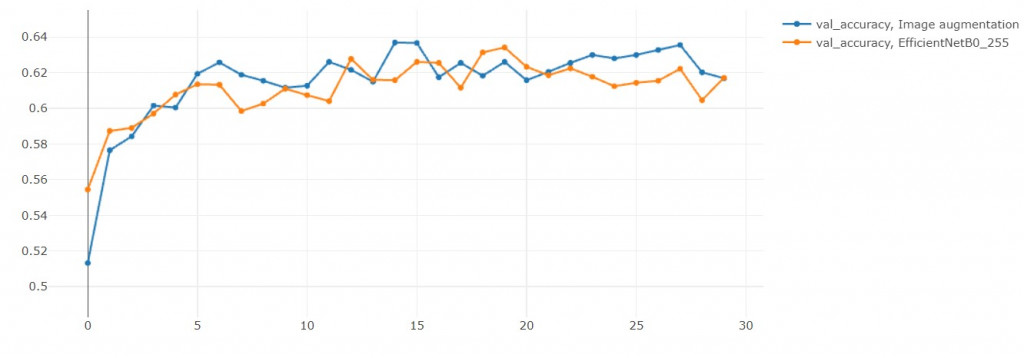
雖然說Over sampling會容易overfitting,
但是和EFN_base比起來,
EFN_AUG反而沒有那麼overfitting。
這是個有趣的現象。
(或許我不小心增強出驗證集的人臉)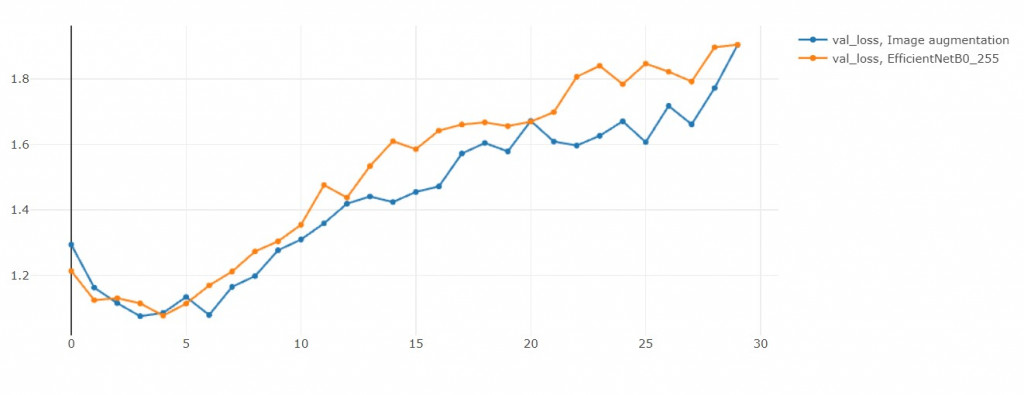
資料擴增有助於解決資料不平衡的問題,
但也要注意擴增時的情況合理性,
像是把人臉旋轉180度就不合理(笑臉變成哭臉),
或是把扭曲到看不出人樣,
也會使表情有所變化。
但是我需要花兩倍的時間才能使Val_loss降低0.001,
這值得嗎? 不值得
但有差嗎? 沒差!
訓練一個模型從半小時變成一小時而已。
所以我還是會用這個技巧在實務上。
那有其他方法處理data imbalance嗎?
有的!我們明天來介紹

 iThome鐵人賽
iThome鐵人賽